Collapse SQL Whitespace
I need a function that collapses whitespace and removes comments from PostgreSQL queries. As described in the Haskell Exercise for AI blog entry, I tried asking Phind and ChatGPT for one and did not get usable results. This blog entry presents my implementation. I am blogging about it just because I would like to take advantage of Linus’s law. Please let me know what I am missing!
I named my function sqlCollapseWhitespace. I decided
against the verb “minimize” because it does not remove unnecessary
whitespace surrounding special characters. For example, consider query
SELECT 1, 2;. This function returns query
SELECT 1, 2;, while a minimized version would be
SELECT 1,2; because whitespace is not necessary after the
comma. This function collapses whitespace but does not minimize it.
Here are some notes about the output of
sqlCollapseWhitespace:
- Output queries never start with whitespace.
- Output queries never end with whitespace.
- Consecutive whitespace and comments after a semicolon are collapsed to a newline.
- All other consecutive whitespace and comments are collapsed to a space.
Here is an overview of the relevant SQL syntax that
sqlCollapseWhitespace supports:
Standard SQL comments are supported. Standard SQL comments start with two dashes and continue until the end of the line.
-- standard SQL commentC-style comments are also supported. C-style comments may be nested, as specified in the SQL standard.
/* C-style comment */ /* /* Nested */ C-style comment */ /* Non-terminated /* C-style comment */Double-quoted identifiers are supported. Whitespace in identifiers is not collapsed.
SELECT foo FROM "foo bar";Single-quoted string syntax is supported. A single quote is included in a single-quoted string using two consecutive single quotes. Backslashes are normal characters in a single-quoted string, not escape characters.
SELECT 'Well, isn''t that special?' AS s;Single-quoted strings separated by whitespace with at least one newline are translated to one single-quoted string. (This syntax is part of the SQL standard!)
SELECT 'foo' 'bar' = 'foobar';PostgreSQL escape string syntax is supported. A single quote is included in an escape string using two consecutive single quotes or by escaping a single quote using a preceding backslash.
SELECT E'''20s' = E'\'20s';PostgreSQL Unicode escape string syntax is supported. A single quote can be included in a Unicode escape string using two consecutive single quotes.
SELECT U&'Travis''s d!0061t!+000061' UESCAPE '!' AS s;PostgreSQL dollar-quoted string syntax is supported. A dollar-quoted string starts with two dollar signs surrounding a (possibly empty) tag and ends with the same. No characters within the string are special, so dollar-quoted strings can be nested as long as they use different tags.
SELECT $abc$ $abcd$ $abcd$ $abc$ AS s;
I wrote sqlCollapseWhitespace in the (“lazy”) style of
the sql
quasiquoter in postgresql-simple.
It traverses the characters of a string and creates the output as it is
evaluated. One major difference, however, is that
sqlCollapseWhitespace is total. The minimizeSpace
function used to implement the sql quasiquoter is partial, and any
errors are thrown at compile time. I need to use
sqlCollapseWhitespace to compare queries, at run time, so
it must not throw errors. “Garbage in,
garbage out.”
The function is about 100 lines long and is included below. The full source is available on GitHub, including a test suite.
Here are some implementation notes:
Like
minimizeSpace,sqlCollapseWhitespaceis implemented using a state machine where states are defined using helper functions. As a convention, state helper functions have names that begin withgo.My initial implementation used an “unrolled” style that gives (slightly) better performance, but I rewrote it to prioritize readability.
The
dropCStyleCommenthelper function uses parametercountto track the nesting level as follows.input: /* /* Nested */ C-style comment */ count: 00011111111110000000000000000000The
goSpacestate uses parametermCas an optional (whitespace) character that should replace the consumed whitespace. ANothingargument is used at the beginning, because output queries should never start with whitespace. If there are no more characters in this state, the empty string is returned, because output queries should never end with whitespace.When a single-quoted string is ended, additional states are required to check for single-quoted string concatenation. This implementation does not output the closing single quote until it is determined that there is no further concatenation. The
goStringSQEndstate cannot useisSpacebecause it has to specifically check for newlines. ThehasSpaceparameter tracks if any whitespace or comment has been consumed so that a space can be output when there is no concatenation. ThegoStringSQEndNewlinestate is able to useisSpacebecause a newline has already been seen.The
goStringDSstate accumulates the tag in reverse order and then callsreversewhen passing it to thegoStringDSstate. This is a common technique for non-terrible performance when using linked-lists such asString.
That following is an approximate diagram of the state machine. Multiple transitions between the same states are shown using a single transition with the inputs shown on separate lines. All shown states have transitions to the end state, but this is not shown so that the diagram is readable. Input syntax varies, and there is logic that cannot be concisely reflected in a diagram, so please see the code for details.
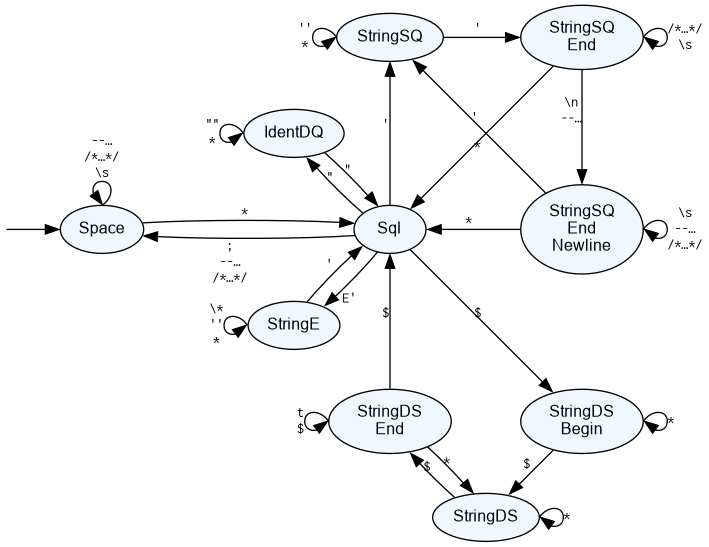
Code
sqlCollapseWhitespace :: String -> String
sqlCollapseWhitespace = goSpace Nothing
where
dropStdComment :: String -> String
dropStdComment = dropWhile (/= '\n')
dropCStyleComment :: Int -> String -> String
dropCStyleComment !count = \case
('*':'/':xs)
| count < 1 -> xs
| otherwise -> dropCStyleComment (count - 1) xs
('/':'*':xs) -> dropCStyleComment (count + 1) xs
(_x:xs) -> dropCStyleComment count xs
[] -> []
goSpace :: Maybe Char -> String -> String
goSpace mC xs = case dropWhile isSpace xs of
('-':'-':ys) -> goSpace mC $ dropStdComment ys
('/':'*':ys) -> goSpace mC $ dropCStyleComment 0 ys
[] -> []
ys -> case mC of
Just c -> c : goSql ys
Nothing -> goSql ys
goSql :: String -> String
goSql = \case
('"':xs) -> '"' : goIdentDQ xs
('\'':xs) -> '\'' : goStringSQ xs
('$':xs) -> '$' : goStringDSBegin "" xs
(';':xs) -> ';' : goSpace (Just '\n') xs
('-':'-':xs) -> goSpace (Just ' ') $ dropStdComment xs
('/':'*':xs) -> goSpace (Just ' ') $ dropCStyleComment 0 xs
('E':'\'':xs) -> 'E' : '\'' : goStringE xs
(x:xs)
| isSpace x -> goSpace (Just ' ') xs
| otherwise -> x : goSql xs
[] -> []
goIdentDQ :: String -> String
goIdentDQ = \case
('"':'"':xs) -> '"' : '"' : goIdentDQ xs
('"':xs) -> '"' : goSql xs
(x:xs) -> x : goIdentDQ xs
[] -> []
goStringSQ :: String -> String
goStringSQ = \case
('\'':'\'':xs) -> '\'' : '\'' : goStringSQ xs
('\'':xs) -> goStringSQEnd False xs
(x:xs) -> x : goStringSQ xs
[] -> []
goStringSQEnd :: Bool -> String -> String
goStringSQEnd hasSpace = \case
('\n':xs) -> goStringSQEndNewline xs
('-':'-':xs) ->
-- avoid unused @hasSpace@
goStringSQEndNewline $ dropStdComment xs
('/':'*':xs) -> goStringSQEnd True $ dropCStyleComment 0 xs
xs@(y:ys)
| isSpace y -> goStringSQEnd True ys
| hasSpace -> '\'' : ' ' : goSql xs
| otherwise -> '\'' : goSql xs
[] -> "'"
goStringSQEndNewline :: String -> String
goStringSQEndNewline xs = case dropWhile isSpace xs of
('\'':ys) -> goStringSQ ys
('-':'-':ys) -> goStringSQEndNewline $ dropStdComment ys
('/':'*':ys) -> goStringSQEndNewline $ dropCStyleComment 0 ys
[] -> "'"
ys -> '\'' : ' ' : goSql ys
goStringE :: String -> String
goStringE = \case
('\\':x:xs) -> '\\' : x : goStringE xs
('\'':'\'':xs) -> '\'' : '\'' : goStringE xs
('\'':xs) -> '\'' : goSql xs
(x:xs) -> x : goStringE xs
[] -> []
goStringDSBegin :: String -> String -> String
goStringDSBegin acc = \case
('$':xs) -> '$' : goStringDS (reverse acc) xs
(x:xs) -> x : goStringDSBegin (x : acc) xs
[] -> []
goStringDS :: String -> String -> String
goStringDS tag = \case
('$':xs) -> '$' : goStringDSEnd tag (tag, xs)
(x:xs) -> x : goStringDS tag xs
[] -> []
goStringDSEnd :: String -> (String, String) -> String
goStringDSEnd tag = \case
(t:ts, x:xs)
| x == t -> x : goStringDSEnd tag (ts, xs)
| x == '$' -> x : goStringDSEnd tag (tag, xs)
| otherwise -> x : goStringDS tag xs
([], '$':xs) -> '$' : goSql xs
(_ts, xs) -> goStringDS tag xs