Codd Design Ideas
Codd is a utility for managing PostgreSQL migrations, written in Haskell. I quite like it, and I have been thinking about the design space. This blog entry describes my current design ideas.
Codd Overview
Codd is schema migration software that maintains an ordered list of applied SQL migrations. Each database includes a table that registers which of these migrations have been applied to that database. Codd maintains a low-level representation of the database and associated roles, which is retrieved from the database, not computed from the SQL migration files. Migrations are generally tested before being put into production, so Codd knows the expected state of the database after applying a migration and can check that the database state matches the expected state within the migration transaction.
Please see the Codd repository for more details about Codd features.
Terminology
The word schema is used for more than one concept. I use it in the general sense (reference). It is (IMHO unfortunately) also used by PostgreSQL to describe namespaces (reference). If I ever talk about this use, I specify PostgreSQL schema.
Codd represents the state of a database (and associated roles) at a given time using JSON, either organized hierarchically by key using many files or in a single JSON file. Migrations are the arrows (morphisms) between these database states. In this blog entry, I use indices to distinguish different states and migrations, and I call the JSON representation a snapshot to emphasize that it is the state at a specific time.
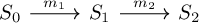
The initial state (\(S_0\)) is empty. The first migration (\(m_1\)) migrates a database from \(S_0\) to \(S_1\), the second migration (\(m_2\)) migrates a database from \(S_1\) to \(S_2\), etc.
Schema migration must manage databases across a number of different types of environments. I use the following terminology:
- Production environments: used by customers, contain sensitive data, have SLOs/SLAs
- Demonstration environments: used by sales staff and/or potential customers, may contain sensitive data, minimizing issues and downtime is “best effort”
- Staging environments: used to test before pushing to production or demonstration environments
- Testing environments: used by developers to test during development
- Development environments: local environments each used by single developers during development
State Representation
With normal usage, Codd maintains a single snapshot, which represents the state of the database with all of the applied migrations. When managing the filesystem using Git, one can inspect previous states of the database by checking out previous commits, but this requires users to search for an appropriate commit and makes it difficult to reference multiple states.
Note that Codd snapshots are low-level representations. Each snapshot is specific to the version of PostgreSQL that is used to take the snapshot. See the Codd Experiment 2: PostgreSQL Upgrade blog entry for details.
It would be interesting to instead maintain the state of the database across all migrations. This is analogous to how Git is designed. The full history of changes is stored in a Git repository, while the Git workspace contains the state at a specific point in time. With such a design, database migration software can reference all states, which makes many of the following features possible.
A full history of database state across all applied migrations should work across multiple PostgreSQL versions. The software should therefore use a general representation that provides a “view” for each supported version of PostgreSQL.
Migration Tracking
Codd maintains migrations that have been applied to any database, on
the filesystem. A migration is applied using the codd add
command. The migration is appended to the list and the snapshot is
updated only if the migration is successful. Migrations are ordered by
the time that they were added, and the codd up command is
used to synchronize a database with the current list of applied
migrations.
A benefit of this design is that users do not need to worry about including index numbers in migration filenames. A drawback is that migrations that have not been applied must be managed separately. See the Codd Experiment blog entry for details about how I am currently doing this.
I have been thinking about not tracking applied migrations in this way. The migrations directory could instead contain all migration files whether they have been applied or not. Users need to worry about index numbers, but this is necessary to support other features anyway.
A basic migration file is named like
NNNN-DESCRIPTION.sql. NNNN is a zero-padded,
four-digit index, starting from 1. Other types of migrations are
described below. For example, file 0001-init-schema.sql is
a first migration that initializes the database schema.
A migration file may be changed while it is still under development,
but it should not be changed once it has been used in a production or
demonstration environment. I recommend setting the file as read-only (chmod
0444) as a way to remind developers that a migration should
no longer be changed.
Verify Scripts
One feature that some schema migration tools have is verify scripts. A verify script is used to verify that a migration is successful. It is run in the same transaction as a migration, and any error raised causes a rollback.
A verify script has extension .verify.sql and
corresponds to the migration file that has the same name but with a
.sql extension. For example, file
0001-init-schema.verify.sql is a verify script for the
above example migration.
Codd checks that the database state matches the expected state, so verify scripts do not need to check schema changes. Migrations often have to deal with data, however, and verify scripts can be useful for verifying critical data.
Migration Inverses
A migration inverse reverts a migration. The term inverse is borrowed from mathematics: a migration composed with its inverse is congruent to the identity function. In the following diagram, migration \(m_2\) migrates from state \(S_1\) to state \(S_2\). Migration \(m_2^{-1}\) is the corresponding inverse, which migrates from state \(S_2\) back to \(S_1\).
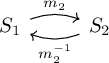
Migration inverses are critical for minimizing downtime when there is an unexpected issue, which may not even be related to the database migration. Some companies even require developing and testing migration inverses for all migrations to released services before applying them to production or demonstration environments.
A migration inverse has extension .inverse.sql and
corresponds to the migration that has the same name but with a
.sql extension. For example, file
0001-init-schema.inverse.sql is an inverse for the above
example migration. A migration inverse may have a verify script. For
example, file 0001-init-schema.inverse.verify.sql is a
verify script for this inverse.
Developers must check that migration inverses are correct. For example, the inverse in the above diagram must satisfy the following laws, where \(1_{S_1}\) represents the identity function for \(S_1\), etc.
\[ 1_{S_1} \cong m_2^{-1} \circ m_2 \]
\[ 1_{S_2} \cong m_2 \circ m_2^{-1} \]
Due to the way that states are constructed, it should be sufficient to just check the first one. Checking requires snapshots for both database states. If the software maintains the state of the database across all migrations, then a command can be provided to make checking inverses very easy.
This cannot be easily done with Codd because only the latest snapshot is stored. Users can check inverses by copying the snapshot and using a temporary development database, however, as follows.
- At state \(S_1\), make a copy of the current schema directory \(s_a\) as \(s_b\).
- Update the
CODD_EXPECTED_SCHEMA_DIRenvironment variable to point to \(s_b\). - Apply migration \(m_1\). This updates schema directory \(s_b\) to represent state \(S_2\).
- Apply migration inverse \(m_1^{-1}\). This updates schema directory \(s_b\) to represent the new state.
- Update the
CODD_EXPECTED_SCHEMA_DIRenvironment variable to point to \(s_a\), which still represents state \(S_1\). - Run
codd verify-shemato check the new state against state \(S_1\). The inverse reverted the migration if verification is successful. - Cleanup by removing the added migration and inverse from the
CODD_MIGRATION_DIRSdirectory, remove schema directory \(s_b\), and discard the temporary database.
Multi-Step Migrations
IMHO, two things can make database migrations challenging. One is “data migration,” where changes to the schema necessitate transformation of data in order to maintain database constraints. The other is upgrading a distributed system without downtime. Simple migrations can be done using a single step, but complex migrations almost always require multiple steps, usually because software that uses the database must also be upgraded.
See the Multi-Step Migration section of the Codd Experiment blog post for an example of renaming a column. If software is using the old column name, then simply renaming the column causes that software to fail. In that example, the database is migrated to an intermediate state that is compatible with both old and new versions of the software, the software is upgraded to the new version (perhaps using a phased/gradual rollout), and finally the database is migrated to the target state.
Such migrations must be carefully prepared and tested when the cost of production issues is high. One must be especially careful with destructive migrations. For example, destructive commands are often isolated in a separate step that is only applied after backups have been taken and it is certain that the target data is no longer needed. The above example does not remove any data and only requires two steps, while a destructive migration may use a third step to perform deletions or drop tables.
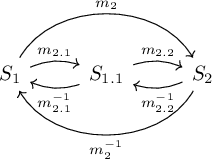
The following diagram illustrates a two-step migration from state \(S_1\) to state \(S_2\), via intermediate state \(S_{1.1}\). Migrations \(m_{2.1}\) and \(m_{2.2}\) may have inverses \(m_{2.1}^{-1}\) and \(m_{2.2}^{-1}\), respectively. Optionally, migration \(m_2\) transitions from state \(S_1\) to state \(S_2\) without an intermediate state, with \(m_2^{-1}\) as the inverse.
Multi-step migration files are named like
NNNN.S-DESCRIPTION.sql. S is the migration
step number, starting from 1 for each index. For example, files
0002.1-rename-employee-name.sql and
0002.2-rename-employee-name.sql could be used to implement
a two-step migration to rename a column. Inverses for these migrations
would be in files 0002.1-rename-employee-name.inverse.sql
and 0002.2-rename-employee-name.inverse.sql, respectively.
Each of these may have a verify script, if necessary. File
0002-rename-employee-name.sql may migrate without steps,
with file 0002-rename-employee-name.inverse.sql as the
inverse.
Developers must check that migration inverses for each step are correct. For example, the inverses for the steps in the above diagram must satisfy the following laws.
\[ 1_{S_1} \cong m_{2.1}^{-1} \circ m_{2.1} \]
\[ 1_{S_{1.1}} \cong m_{2.1} \circ m_{2.1}^{-1} \]
\[ 1_{S_{1.1}} \cong m_{2.2}^{-1} \circ m_{2.2} \]
\[ 1_{S_2} \cong m_{2.2} \circ m_{2.2}^{-1} \]
If a migration without steps is provided, developers must check that it is congruent to using the steps. With the above example diagram, the following must be satisfied.
\[ m_2 \cong m_{2.2} \circ m_{2.1} \]
If the migration without steps has an inverse, developers must check that is is correct and is congruent to using the step inverses. With the above example diagram, the following must be satisfied.
\[ 1_{S_1} \cong m_2^{-1} \circ m_2 \]
\[ 1_{S_2} \cong m_2 \circ m_2^{-1} \]
\[ m_2^{-1} \cong m_{2.1}^{-1} \circ m_{2.2}^{-1} \]
The number of required checks increases with the number of steps. If the software maintains the state of the database across all migrations, then this can all be automated.
Checkpoints
A checkpoint is a migration that is equivalent to all previous migrations.
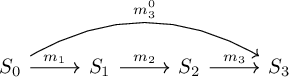
In this diagram, migration \(m_3^0\) is a checkpoint that is equivalent to the first three migrations.
\[ m_3^0 \cong m_3 \circ m_2 \circ m_1 \]
Checkpoints are named like
NNNN-DESCRIPTION.checkpoint.sql. For example, file
0003-add-phone-table.checkpoint.sql is equivalent to the
first three migrations. Note that checkpoints can only be applied to
\(S_0\), the empty state. Also note
that checkpoints should not be for individual steps. (There is no
.S in a checkpoint file name.)
Developers must check that checkpoints are valid. If the software maintains the state of the database across all migrations, then this can be automated. It can be checked manually using Codd in a manner that is similar to the above inverse check.
One use of checkpoints is to clean up the database before release. There may be many changes during early development, and migrations may add columns in a non-optimal order. A checkpoint may be used to initialize a database that is equivalent to all previous migrations except that it changes the column order for good alignment (tutorial). Automated checking of checkpoints should therefore have an option to ignore column order.
Migration Management
A table in the database should track the full migration history, including applications of any inverses. Note that entries may differ in different databases for a number of reasons. Inverses may be needed in some database and not others, and different databases may be initialized using different checkpoints.
The final entry indicates the expected state of the database, and the expected state is \(S_0\) (the empty state) when there are no entries. This state determines which migrations are valid to apply to that database.
A database in state \(S_0\) should be confirmed empty before applying any migrations. Valid migrations include the following.
- A first migration (Example:
0001-init-schema.sql) - A first migration step (Example:
0001.1-init-schema.sql) - A checkpoint (Example:
0121-use-beam-conventions.checkpoint.sql)
As an example of migrating from a different state, consider a database that is in state \(S_3\). The software should confirm that the database state matches the expected state before apply any migrations. This can only be done if the software maintains the state of the database across all migrations. Valid migrations include the following.
- A migration with index 4 (Example:
0004-add-company.sql) - A first migration step with index 4 (Example:
0004.1-add-company.sql) - A migration inverse with index 3 (Example:
0003-add-phone-table.inverse.sql) - A last migration step inverse with index 3 (Example:
0003.2-rename-employee-name.inverse.sql)
For any of these migrations, verify scripts can be run as part of the transaction, if they exist. The software should also check that the final database state matches the target state, as part of the transaction.
User Interface
What kind of user interface could implement the above ideas? I use
program name edgar to describe proposed commands. This
distinguishes them from actual codd commands and hopefully
avoids any confusion. (Edgar F. Codd
invented the relational model.)
Database Commands
These commands are for working with a specific database.
edgar database status checks the status
of a database. It first checks if the table that tracks migrations even
exists. When it exists, it uses entries of that table to determine the
expected state, as described above. Once the expected state is
determined, the actual database state can be compared. This command must
never modify the database.
This command is roughly equivalent to
codd verify-schema, but it is much more versatile. Notably,
it can check the status of databases that are not at the most recent
state.
edgar database migrations lists
migrations that have been applied to the database. It first checks if
the table that tracks migrations even exists. If it exists, it lists the
applied migrations. Command options can be used to determine how much
detail is displayed. This command must never modify the database.
There is no Codd equivalent to this command, but one could easily be implemented.
edgar database migrate MIGRATION
migrates the database. It first checks if the table that tracks
migrations even exists. When it exists, it uses entries of that table to
determine the expected state, as described above. Once the expected
state is determined, the actual database state can be compared, and the
command exits with an error if the database state does not match the
expected state. The on-disk migrations form a graph of states and
transitions, and the software must determine a path from the database
state to the specified migration (target state). If there is no path,
the command exits with an error. If there is a path, then the
migration(s) are applied to the database. When the path traverses states
that have multi-step migrations and a non-multi-step migration is
available, the non-multi-step migration should be used by default. When
the initial state is \(S_0\) and a
checkpoint can be used, the most recent applicable checkpoint should be
used by default. When a migration is applied for the first time, the new
state is saved. This command should have a --dry-run option
so that users can see the migration plan without performing any
migrations. An --interactive option could be provided to
allow users to choose to proceed or not. A --multi-step
option could also be used to force use of multi-step migrations. A
--no-checkpoint option could be used to avoid use of
checkpoints.
This command is roughly equivalent to codd up, but it is
much more versatile. Notably, it can be used to migrate to states that
are not the most recent. It can also migrate “backwards” using
inverses.
edgar database snapshot SNAPSHOT
creates a snapshot of a database. This snapshot may not correspond to
any valid state. This command must never modify the database.
This command is equivalent to codd write-schema.
Verify Commands
These commands are for verifying inverse and checkpoint validity. These commands could be implemented using temporary databases.
None of these commands are possible to implement in Codd because Codd only maintains the current/latest snapshot.
edgar verify inverse INVERSE_MIGRATION
verifies a migration inverse.
edgar verify checkpoint CHECKPOINT_MIGRATION
verifies a checkpoint migration. Option
--ignore-column-order can be specified to ignore column
order.
State Commands
These commands are for working with database states and snapshots. They do not use any database.
edgar state list lists the available
states. This is \(S_0\) and a state for
each migration that has been applied, including intermediate states for
migration steps. Command options can be used to determine how much
detail is displayed, such as listing migrations that are possible from
each state.
A similar command could be implemented for Codd based on the list of applied migrations, but it would be pointless.
edgar state graph creates a graph that
illustrates states and available migrations, perhaps writing Graphviz source code. Command
options/arguments could be used to render a subset of the graph, select
which types of migrations to display, etc.
This command is not relevant to Codd because Codd does not distinguish between different types of migrations.
edgar state export STATE SNAPSHOT
exports a state to a snapshot. This makes it easy for users to inspect
any state of the database.
This command is not relevant to Codd because Codd only tracks the current/latest state. Codd users instead use Git to checkout a revision of the repository that has a snapshot for the target state.
edgar state convert SOURCE_SNAPSHOT DEST_SNAPSHOT
converts between snapshot formats. I considered using commands
pack to convert from a hierarchical snapshot to a JSON
snapshot and unpack to convert from a JSON snapshot to a
hierarchical snapshot, but using convert leaves room for
adding more snapshot formats in the future. Future formats could
possibly include archives of hierarchical JSON, YAML, etc.
A similar command could be implemented in Codd.
edgar state diff STATE|SNAPSHOT STATE|SNAPSHOT
compares states/snapshots. This is useful during development and for
debugging issues.
A similar command that just compares snapshots could be implemented in Codd. Codd users should use Git to reference previous snapshots.
edgar state search SNAPSHOT searches
for states that are most similar to the specified snapshot. Note that is
uses comparison, not equality, so that users can find the most similar
states.
This command is not possible to implement in Codd because Codd only tracks the current/latest state.
Conclusion
This is a pretty good initial draft of many features that I would love to have. It may serve as inspiration in the development of Codd.
Some features be implemented while others may never be implemented. Storing the state of the database across all migrations is required to implement the most useful features, but that would be a major change. Now that I have a description of the interface that I want, perhaps I can start to think about how to implement scripts that use Codd to achieve the same goals!