Codd Migration Inverses
I talked a bit about migration inverses in the Codd Experiment blog entry, where I created some test inverses but did not actually use them. I wrote much more about them in the Codd Design Ideas blog entry, which explains the requirements for inverses in terms of database state. In this blog entry, I experiment with how migration inverses can actually be managed with Codd.
In Codd Design Ideas, I describe the features that I wish I had. Migrations are the arrows between states of the database. This forms a digraph, and it is important to note that it is not necessarily linear. While database migrations are generally managed linearly, unforeseen issues may result in one or more migrations to be inverted and not used in the long run.
I use numeric indices to make diagrams easy to read, but additional notation is necessary to illustrate nonlinear graphs. The following diagram uses additional subscripts.
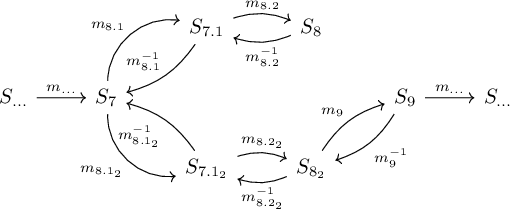
Here is the scenario. Previous migrations lead to state \(S_7\). A two-step migration is created, using migrations \(m_{8.1}\) and \(m_{8.2}\) to migrate from state \(S_7\) to state \(S_8\) via intermediate state \(S_{7.1}\). These migrations have inverses, and they are used to revert to state \(S_7\) due to an unforeseen issue in production. It is determined that a different approach is needed, and a new two-step migration is created, using migrations \(m_{8.1_2}\) and \(m_{8.2_2}\) to migrate from state \(S_7\) to state \(S_{8_2}\) via intermediate state \(S_{7.1_2}\). This works out, so subsequent migration \(m_9\) can be used to migrate from state \(S_{8.2_2}\) to state \(S_9\), etc.
On the filesystem, these migrations may be implemented in files named
like the following. Migrations may not be modified after use in
production, but developers should document the reason for the new
migrations within those migration files. They may optionally include an
indication in the description in the filename, like the -2
suffix in the examples below, but this is just a convenience.
0008.1-refactor-company-pkey.sql
0008.1-refactor-company-pkey.inverse.sql
0008.2-refactor-company-pkey.sql
0008.2-refactor-company-pkey.inverse.sql
0008.1-add-company-fkey-2.sql
0008.1-add-company-fkey-2.inverse.sql
0008.2-add-company-fkey-2.sql
0008.2-add-company-fkey-2.inverse.sql
0009-add-company_event.sql
0009-add-company_event.inverse.sqlWhen migrating from a previous state such as \(S_0\) to state \(S_9\), the reverted migrations are not used because the shortest path uses the new migrations. Note that state indices result in concise diagrams, but states should be referenced using hashes when implemented.
Edit: I have since thought about how to implement this, and I realized that these filenames are of course not sufficient to create the digraph. In the above example, migration \(m_9\) cannot know which state is the source. As I write this, I am still thinking about how to best resolve this issue. Perhaps (re)moving dead-end branches would be the most user friendly.
Codd
How should this be managed using Codd? Codd maintains a list of
applied migrations, but migration inverses should never be added to that
list. There is no need to apply a migration and then its inverse when
running codd up, for example. In addition, one must be
careful to check the database against the on-disk snapshot for the
appropriate state.
The following lists the high-level steps for the above scenario.
- Apply migration \(m_{8.1}\)
- The database state must match the on-disk snapshot representing state \(S_{7.1}\).
- Upgrade software
- Apply migration \(m_{8.2}\)
- The database state must match the on-disk snapshot representing state \(S_8\).
- Discover critical issue
- Apply migration \(m_{8.2}^{-1}\)
- The database state must match the on-disk snapshot representing state \(S_{7.1}\).
- This inverse should not be added to the list of applied migrations. Migration \(m_{8.2}\) should instead be removed from the list.
- Downgrade software
- Apply migration \(m_{8.1}^{-1}\)
- The database state must match the on-disk snapshot representing state \(S_7\).
- This inverse should not be added to the list of applied migrations. Migration \(m_{8.1}\) should instead be removed from the list.
- Develop new migrations
- Apply migration \(m_{8.1_2}\)
- The database state must match the on-disk snapshot representing state \(S_{7.1_2}\).
- Upgrade software
- Apply migration \(m_{8.2_2}\)
- The database state must match the on-disk snapshot representing state \(S_{8_2}\).
- Apply migration \(m_9\)
- The database state must match the on-disk snapshot representing state \(S_9\).
Codd does not provide any support for migration inverses. As an example, the following is one way to implement step 5. Note that Git state cannot simply be reverted because the branch may have many other unrelated commits.
- Determine a Git revision that has a snapshot representing state \(S_{7.1}\).
- Remove the current snapshot.
git rm -rf var/codd-schema
- Copy the snapshot representing state \(S_{7.1}\) from the old revision.
git checkout REVISION var/codd-schema
- Apply migration \(m_{8.2}^{-1}\) manually. Codd is not used because we do not want to add this migration to the list of applied migrations or modify the current snapshot.
- Verify the database state against the snapshot (representing state \(S_{7.1}\)).
While not difficult, there may be a lot of steps in total, particularly when dealing with more than one database. In this case, use of a checklist might be warranted.